- Published on
SEO for DNN Multisite Instances
- Authors
- Name
- Paras Daryanani
- @parasdaryanani


Are you having trouble performing SEO for DNN websites in a multisite instance? The main drawback in a multi-site instance is that there is just a single robots.txt file shared across all the portals.
Ideally you'd want a standalone robots.txt file for each portal. Fortunately, this is achievable using the Microsoft URL Rewrite IIS extension (official), which can be downloaded from here.
Once downloaded and installed, you can follow Bruce Chapman's tutorial on how to setup robots.txt files for multiple portals. This is a fairly straightforward process and can be configured within minutes.
Now while Bruce's solution is 100% effective, I had to modify this for my case, where I had to optimise a DNN based SaaS website that contained almost 300 child portals, each of which served as a white-labelled website.
If I stuck with with Bruce's solution as-is, I would have to create almost 300 robots.txt files, prefixed with portal aliases and while this is a scriptable task, I didn't think it was practical in my case.
I was asked to remove the parent portal (say, hostportal.com) from search engines (i.e., its pages, files and all other resources that were indexed), while all child portals had to be indexed as usual, without any changes.
So, to do this, I implemented a modified version of Bruce's solution, and I made http://hostportal.com/robots.txt look like this:
# Begin robots.txt file
User-agent: *
Disallow: /
User-agent: msnbot
Disallow: /
User-agent: Slurp
Disallow: /
User-agent: Googlebot
Disallow: /
User-agent: Yahoo Pipes 1.0
Disallow: /
# End of robots.txt file
I did this by creating a new file called hostportal.com.robots.txt in the root directory of the DNN instance, with the above content.
Following this, I added the following configuration code in the web.config, under the <system.webServer> section:
<rewrite>
<rules>
<rule name="multi-portal robots files" stopProcessing="true">
<match url=".+" />
<conditions>
<add input="{HTTP_HOST}" pattern="hostportal.com" />
<add input="{REQUEST_FILENAME}" pattern="robots.txt" />
</conditions>
<action type="Rewrite" url="hostportal.com.{C:0}" logRewrittenUrl="true" />
</rule>
</rules>
</rewrite>
The only change I made to Bruce's solution, was that I added the following line,
<add input="{HTTP_HOST}" pattern="hostportal.com" />
which applies the rule only to hostportal.com, such that when you, or the search engine crawler visits http://hostportal.com/robots.txt, IIS serves the request using the file called hostportal.com.robots.txt. All other portals remain unaffected and use the common DNN robots.txt within the instance, as I was happy with the default behaviour of the child portals.
And there you have it! One portal invisible to search engines, while all others are indexed as usual and provide separate sitemaps as generated by DNN, so that you can SEO each of them if necessary.
UPDATE: 30/01/2017
This update is long overdue!A couple of weeks after I deployed this solution, I discovered that the custom robots.txt file didn't really affect the visibility of any of the webpages of the parent portal. After breaking my head for some time, I realised that the pages had already been indexed and my shiny little custom robots.txt file was in fact making the situation worse, because the search engines could not even access pages in order to check whether or not to display them in search results.
Whoops, right? Both Google and Bing suggested to add NOINDEX and NOFOLLOW to the robots META tag in the page header instead and in fact allow the webpages to be accessed by search engine robots. But, as I mentioned before, I had to block the files and other resources from being indexed, so my effort didn't completely go to waste. I thereafter modified the custom robots.txt file to deny access to directories where files were stored.
As for the META tags changes, DNN can readily take care of this. Here's how it's done: you go to the portal in question, navigate to the page(s) that you want to block from search engines, go to Page Settings > Advanced Settings > Other Settings and deselect the checkbox, as shown:
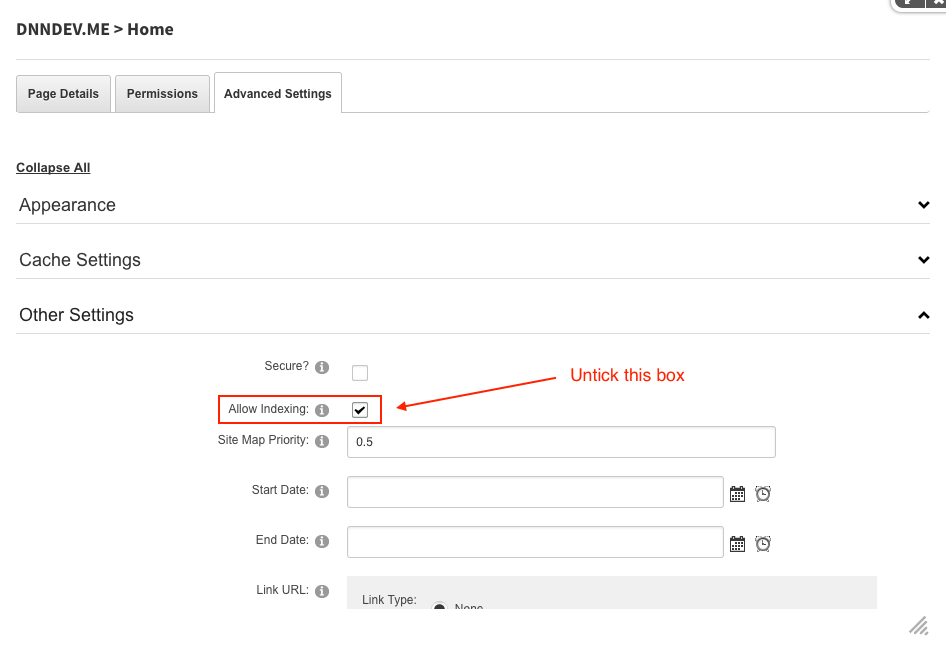
When you untick the box, it changes the robots META tag to look like this,
<META NAME="ROBOTS" CONTENT="NOINDEX, NOFOLLOW">
which is exactly what Google and Bing expect and in my case after doing so, within 24 hours the pages disappeared from search results.
To summarise: use the robots META tag with "NOINDEX, NOFOLLOW" to block your pages from search engines and use the robots.txt method for blocking resources like images, documents and other files that you have stored in any directory of your website.
I hope this article was useful to you and if you have any questions/ comments/ doubts or suggestions, please feel free to comment below and discuss.